Domain 类是任何商业应用的核心。 他们保存事务处理的状态,也处理预期的行为。 他们通过关联联系在一起, one-to-one 或
one-to-many。
GORM 是 Grails对象关联映射 (GORM)的实现。在底层,它使用 Hibernate
3 (一个非常流行和灵活的开源ORM解决方案),
但是因为Groovy天生的动态性,实际上,对动态类型和静态类型两者都支持,由于Grails的规约,只需要很少的配置涉及Grails domain
类的创建。
你同样可以在Java中编写 Grails domain 类。 请参阅在 Hibernate
集成上如果在Java中编写 Grails domain 类, 不过,它仍然使用动态持久方法。下面是GORM实战预览:
def book = Book.findByTitle("Groovy in Action")book
.addToAuthors(name:"Dierk Koenig")
.addToAuthors(name:"Guillaume LaForge")
.save()
grails create-domain-class Person
grails-app/domain/Person.groovy
位置上创建类,如下:
如果在 DataSource
上设置dbCreate属性为"update", "create" or "create-drop", Grails
会为你自动生成/修改数据表格。
你可以通过添加属性来自定义类:
class Person {
String name
Integer age
Date lastVisit
}Create
为了创建一个 domain 类,可以使用 Groovy new操作符, 设置它的属性并调用 save:
def p = new Person(name:"Fred", age:40, lastVisit:new Date())
p.save()
Read
Grails 会为你的domain类显式的添加一个隐式 id
属性,便于你检索:
def p = Person.get(1)
assert 1 == p.id
Person对象
。 你同样可以使用 read 方法加载一个只读状态对象:
在这种情况下,底层的 Hibernate 引擎不会进行任何脏读检查,对象也不能被持久化。
注意,假如你显式的调用 save 方法,对象会回到 read-write 状态.
Update
更新一个实体, 设置一些属性,然后,只需再次调用 save:
def p = Person.get(1)
p.name = "Bob"
p.save()
Delete
删除一个实体使用 delete
方法:
def p = Person.get(1)
p.delete()
Book
类可能拥有 title, release date,ISBN等等。 在后面章节将展示如何在GORM中进行domain建模。
创建domain类,你可以运行 create-domain-class
,如下:
grails create-domain-class Book
grails-app/domain/Book.groovy类:
如果你想使用 packages 你可以把
Book.groovy类移动到 domain 目录的子目录下,并按照Groovy (和 Java)的 packaging 规则添加正确的 package
。
上面的类将会自动映射到数据库中名为 book的表格 (与类名相同).
可以通过 ORM Domain Specific Language定制上面的行为。
现在,你可以把这个domain类的属性定义成Java类型。 例如:
class Book {
String title
Date releaseDate
String ISBN
}releaseDate
映射到 release_date列。 SQL类型会自动检测来自Java的类型 , 但可以通过 Constraints
或 ORM
DSL定制。
关联定义了domain类之间的相互作用。除非在两端明确的指定,否则关联只存在被定义的一方。
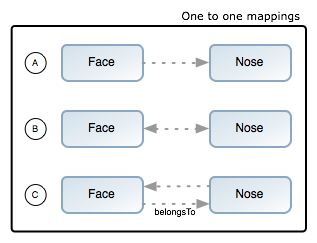
one-to-one 关联是最简单的种类,它只是把它的一个属性的类型定义为其他domain类。 考虑下面的例子:
Example A
class Face {
Nose nose
}
class Nose {
}Face到 Nose的one-to-one单向关联。
为了使它双向关联,需要定义另一端,如下:
Example B
class Face {
Nose nose
}
class Nose {
Face face
}Example C
class Face {
Nose nose
}
class Nose {
static belongsTo = [face:Face]
}belongsTo 来设置Nose
"属于" Face。结果是,我们创建一个Face并save 它,数据库将 级联 更新/插入 Nose:
new Face(nose:new Nose()).save()
Face导致一个错误:
new Nose(face:new Face()).save() // will cause an error
belongsTo另一个重要的意义在于,假如你删除一个 Face
实体, Nose 也会被删除:
def f = Face.get(1)
f.delete() // both Face and Nose deleted
belongsTo ,deletes 将不被级联,并会得到一个外键约束错误,除非你明确的删除Nose:
// error here without belongsTo
def f = Face.get(1)
f.delete()// no error as we explicitly delete both
def f = Face.get(1)
f.nose.delete()
f.delete()
class Face {
Nose nose
}
class Nose {
static belongsTo = Face
}belongsTo使用map语法声明和明确命名关联。Grails
会把它当做单向。.下面的图表概述了3个示例:
 one-to-many 关联是,当你的一个类,比如
one-to-many 关联是,当你的一个类,比如
Author
,拥有许多其他类的实体,比如
Book
。 在Grails 中定义这样的关联可以使用
hasMany
:
class Author {
static hasMany = [ books : Book ] String name
}
class Book {
String title
}ORM
DSL 允许使用外键关联作为映射单向关联的替代
对于 hasMany 设置,Grails将自动注入一个java.util.Set类型的属性到domain类。
用于迭代集合:
def a = Author.get(1)a.books.each {
println it.title
}Grails中默认使用的fetch策略是 "lazy",
意思就是集合将被延迟初始化。 如果你不小心,这会导致 n+1
问题 。
如果需要"eager" 抓取 ,需要使用 ORM
DSL 或者指定立即抓取作为query的一部分
默认的级联行为是级联保存和更新,但不删除,除非 belongsTo
被指定:
class Author {
static hasMany = [ books : Book ] String name
}
class Book {
static belongsTo = [author:Author]
String title
}mappedBy
指定哪个集合被映射:
class Airport {
static hasMany = [flights:Flight]
static mappedBy = [flights:"departureAirport"]
}
class Flight {
Airport departureAirport
Airport destinationAirport
}class Airport {
static hasMany = [outboundFlights:Flight, inboundFlights:Flight]
static mappedBy = [outboundFlights:"departureAirport", inboundFlights:"destinationAirport"]
}
class Flight {
Airport departureAirport
Airport destinationAirport
}hasMany
,并在关联拥有方定义
belongsTo
:
class Book {
static belongsTo = Author
static hasMany = [authors:Author]
String title
}
class Author {
static hasMany = [books:Book]
String name
}Author
负责持久化关联,并且是唯一可以级联保存另一端的一方 。
例如,下面这个可以进行正常级联保存工作:
new Author(name:"Stephen King")
.addToBooks(new Book(title:"The Stand"))
.addToBooks(new Book(title:"The Shining"))
.save()Book而不保存 authors!
new Book(name:"Groovy in Action")
.addToAuthors(new Author(name:"Dierk Koenig"))
.addToAuthors(new Author(name:"Guillaume Laforge"))
.save()当前,Grails的Scaffolding
特性不支持many-to-many关联, 你必须自己编写关联的管理代码
除了关联不同 domain 类外, GORM 同样支持映射基本的集合类型。比如,下面的类创建一个
nicknames
关联, 它是一个
String
的
Set
实体:
class Person {
static hasMany = [nicknames:String]
}joinTable参数来改变各式各样的连接表映射:
class Person {
static hasMany = [nicknames:String] static mapping = {
hasMany joinTable:[name:'bunch_o_nicknames', key:'person_id', column:'nickname', type:"text"]
}
}---------------------------------------------
| person_id | nickname |
---------------------------------------------
| 1 | Fred |
---------------------------------------------
class Person {
Address homeAddress
Address workAddress
static embedded = ['homeAddress', 'workAddress']
}
class Address {
String number
String code
}
如果你在grails-app/domain目录中定义了一个单独的Address类,
你同样会得到一个表格。如果你不想这样,你可以 利用Groovy在单个文件定义多个类的能力,让grails-app/domain/Person.groovy
文件中的Person类包含 Address类。
GORM 支持从抽象类的继承和具体持久化GORM实体的继承。例如:
class Content {
String author
}
class BlogEntry extends Content {
URL url
}
class Book extends Content {
String ISBN
}
class PodCast extends Content {
byte[] audioStream
}Content父类和各式各样带有更多指定行为的子类。
注意事项
在数据库层, Grails默认使用一个类一个表格的映射附带一个名为class的识别列,
因此,父类 (Content) 和它的子类(BlogEntry, Book
等等.), 共享 相同的表格。
一个类一个表格的映射有个负面的影响,就是你 不能
有非空属性一起继承映射。 另一个选择是使用每个子类一个表格 ,你可以通过 ORM
DSL启用。
不过,
过分使用继承与每个子类一个表格会带来糟糕的查询性能,因为,过分使用链接查询。总之,我们建议:假如你打算使用继承,不要滥用它,不要让你的继承层次太深。
多态性查询
继承的结果是你有能力进行多态查询。比如,在Content使用 list
方法,超类将返回所有Content子类:
def content = Content.list() // list all blog entries, books and pod casts
content = Content.findAllByAuthor('Joe Bloggs') // find all by authordef podCasts = PodCast.list() // list only pod castsSets对象
默认情况下,在中 GORM定义一个 java.util.Set
映射,它是无序集合,不能包含重复元素。 换句话,当你有:
class Author {
static hasMany = [books:Book]
}java.util.Set类型。
问题在于存取时,这个集合的无序的,可能不是你想要的。为了定制序列,你可以设置为 SortedSet:
class Author {
SortedSet books
static hasMany = [books:Book]
}java.util.SortedSet
,这意味着,你的Book类必须实现 java.lang.Comparable:
class Book implements Comparable {
String title
Date releaseDate = new Date() int compareTo(obj) {
releaseDate.compareTo(obj.releaseDate)
}
}List对象
如果你只是想保持对象的顺序,添加它们和引用它们通过索引,就像array一样,你可以定义你的集合类型为
List:
class Author {
List books
static hasMany = [books:Book]
}author.books[0] // get the first book
books_idx的列,它保存着该元素在集合中的索引.
当使用List时,元素在保存之前必须先添加到集合中,否则Hibernate会抛出异常
(org.hibernate.HibernateException: null index column for
collection):
// This won't work!
def book = new Book(title: 'The Shining')
book.save()
author.addToBooks(book)// Do it this way instead.
def book = new Book(title: 'Misery')
author.addToBooks(book)
author.save()
映射(Maps)对象
如果你想要一个简单的 string/value 对map,GROM可以用下面方法来映射:
class Author {
Map books // map of ISBN:book names
}def a = new Author()
a.books = ["1590597583":"Grails Book"]
a.save()class Book {
Map authors
static hasMany = [authors:Author]
}def a = new Author(name:"Stephen King")
def book = new Book()
book.authors = [stephen:a]
book.save()hasMany
属性定义了map中元素的类型,map中的key 必须 是字符串.
集合类型和性能
Java中的 Set 是一个不能有重复条目的集合类型. 为了确保添加到
Set 关联中的条目是唯一的,Hibernate 首先加载数据库中的全部关联.
如果你在关联中有大量的条目,那么这对性能来说是一个巨大的浪费.
这样做就需要 List 类型,
因为Hibernate需要加载全部关联以维持供应.
因此如果你希望大量的记录关联,那么你可以制作一个双向关联以便连接能在反面被建立。例如思考一下代码:
def book = new Book(title:"New Grails Book")
def author = Author.get(1)
book.author = author
book.save()
Author有大量的关联的Book
实例,如果你写入像下面的代码,你可以看到性能的影响:
def book = new Book(title:"New Grails Book")
def author = Author.get(1)
author.addToBooks(book)
author.save()
def p = Person.get(1)
p.save()
def p = Person.get(1)
p.save(flush:true)
def p = Person.get(1)
try {
p.save(flush:true)
}
catch(Exception e) {
// deal with exception
}def p = Person.get(1)
p.delete()
flush 参数:
def p = Person.get(1)
p.delete(flush:true)
flush
参数也允许您捕获在delete执行过程中抛出的任何异常. 一个普遍的错误就是违犯数据库的约束, 尽管这通常归结为一个编程或配置错误.
下面的例子显示了当您违犯了数据库约束时如何捕捉DataIntegrityViolationException:
def p = Person.get(1)try {
p.delete(flush:true)
}
catch(org.springframework.dao.DataIntegrityViolationException e) {
flash.message = "Could not delete person ${p.name}"
redirect(action:"show", id:p.id)
}deleteAll
方法,因为删除数据是discouraged的,而且通常可以通过布尔标记/逻辑来避免.
如果你确实需要批量删除数据,你可以使用 executeUpdate
法来执行批量的DML语句:
Customer.executeUpdate("delete Customer c where c.name = :oldName", [oldName:"Fred"])belongsTo
的设置控制着哪个类"拥有"这个关联.
无论是一对一,一对多还是多对多,如果你定义了 belongsTo
,更新和删除将会从拥有类到被它拥有的类(关联的另一方)级联操作.
如果你 没有 定义 belongsTo
那么就不能级联操作,你将不得不手动保存每个对象.
下面是一个例子:
class Airport {
String name
static hasMany = [flights:Flight]
}
class Flight {
String number
static belongsTo = [airport:Airport]
}Airport 对象,并向它添加一些 Flight
它可以保存这个 Airport 并级联保存每个flight,因此会保存整个对象图:
new Airport(name:"Gatwick")
.addToFlights(new Flight(number:"BA3430"))
.addToFlights(new Flight(number:"EZ0938"))
.save()Airport 所有跟它关联的 Flight也都将会被删除:
def airport = Airport.findByName("Gatwick")
airport.delete()belongsTo 去掉的话,上面的级联删除代码就了.
不能工作. 为了更好地理解, take a look at the
summaries below that describe the default behaviour of GORM with regards
to specific associations.
设置了belongsTo的双向一对多
class A { static hasMany = [bees:B] }
class B { static belongsTo = [a:A] }belongsTo,那么级联策略将设置一的一端为"ALL",多的一端为"NONE".
单向一对多
class A { static hasMany = [bees:B] }
class B { }belongsTo单向一对多关联,那么级联策略设置将为"SAVE-UPDATE".
没有设置belongsTo的双向一对多
class A { static hasMany = [bees:B] }
class B { A a }belongsTo的双向一对多关联,那么级联策略将为一的一端设置为"SAVE-UPDATE"
为多的一端设置为"NONE".
设置了belongsTo的单向一对一
class A { }
class B { static belongsTo = [a:A] }belongsTo的单向一对一关联,那么级联策略将为有关联的一端(A->B)设置为"ALL",定义了belongsTo的一端(B->A)设置为"NONE".
请注意,如果您需要进一步的控制级联的行为,您可以参见 ORM
DSL.
在GORM中,关联默认是lazy的.最好的解释是例子:
class Airport {
String name
static hasMany = [flights:Flight]
}
class Flight {
String number
static belongsTo = [airport:Airport]
}def airport = Airport.findByName("Gatwick")
airport.flights.each {
println it.name
}Airport
实例,然后再用一个额外的for each查询逐条迭代 flights
关联.换句话说,你得到了N+1条查询.
根据这个集合的使用频率,有时候这可能是最佳方案.因为你可以指定只有在特定的情况下才访问这个关联的逻辑.
配置立即加载
一个可选的方案是使用立即抓取,它可以按照下面的方法来指定:
class Airport {
String name
static hasMany = [flights:Flight]
static mapping = {
flight fetch:"join"
}
}Airport 实例对应的 flights
关联会被一次性全部加载进来(依赖于映射).
这样的好处是执行更少的查询,但是要小心使用,因为使用太多的eager关联可能会导致你将整个数据库加载进内存.
关联也可以用 ORM
DSL 将关联声明为 non-lazy
使用批量加载Using Batch Fetching
虽然立即加载适合某些情况,它并不总是可取的,如果您所有操作都使用立即加载,那么您会将整个数据库加载到内存中,导致性能和内存的问题.替代立即加载是使用批量加载.实际上,您可以在"batches"中配置Hibernate延迟加载.
例如:
class Airport {
String name
static hasMany = [flights:Flight]
static mapping = {
flight batchSize:10
}
}batchSize 参数,当您迭代 flights
关联, Hibernate 加载10个批次的结果. 例如,如果您一个 Airport 有30个s,
如果您没有配置批量加载,那么您在对Airport的查询中只能一次查询出一个结果,那么要执行30次查询以加载每个flight.
使用批量加载,您对Airport查询一次将查询出10个Flight,那么您只需查询3次.
换句话说, 批量加载是延迟加载策略的优化. 批量加载也可以配置在class级别:
class Flight {
…
static mapping = {
batchSize 10
}
}乐观锁
默认的GORM类被配置为乐观锁。乐观锁实质上是Hibernate的一个特性,它在数据库里一个特别的
version 字段中保存了一个版本号.
version 列读取包含当前你所访问的持久化实例的版本状态的 version
属性:
def airport = Airport.get(10)println airport.version
def airport = Airport.get(10)try {
airport.name = "Heathrow"
airport.save(flush:true)
}
catch(org.springframework.dao.OptimisticLockingFailureException e) {
// deal with exception
}悲观锁
悲观锁等价于执行一个 SQL "SELECT * FOR UPDATE"
语句并锁定数据库中的一行. 这意味着其他的读操作将会被锁定直到这个锁放开.
在Grails中悲观锁通过 lock
方法执行:
def airport = Airport.get(10)
airport.lock() // lock for update
airport.name = "Heathrow"
airport.save()
def airport = Airport.lock(10) // lock for update
airport.name = "Heathrow"
airport.save()
尽管Grails和Hibernate支持悲观所,但是在使用Grails内置默认的
HSQLDB 数据库时不支持。如果你想测试悲观锁,你需要一个支持悲观锁的数据库,例如MySQL.
你也可以使用lock 方法在查询中获得悲观锁。例如使用动态查询:
def airport = Airport.findByName("Heathrow", [lock:true])def airport = Airport.createCriteria().get {
eq('name', 'Heathrow')
lock true
}获取实例列表
如果你简单的需要获得给定类的所有实例,你可以使用 list
方法:
list 方法支持分页参数:
def books = Book.list(offset:10, max:20)
def books = Book.list(sort:"title", order:"asc")
sort
参数是您想要查询的domain类中属性的名字,argument is the name of the domain class property
that you wish to sort on, and the order 参数要么以argument is
either asc for asc结束ending
or要么以 desc for desc结束ending.
根据数据库标识符取回
第二个取回的基本形式是根据数据库标识符取回,使用 get 方法:
你也可以根据一个标识符的集合使用 getAll方法取得一个实例列表:
def books = Book.getAll(23, 93, 81)
Book
类:
class Book {
String title
Date releaseDate
Author author
}
class Author {
String name
}Book 类有一些属性,比如 title,
releaseDate 和 author. 这些都可以按照"方法表达式"的格式被用于 findBy
和 findAllBy
方法:
def book = Book.findByTitle("The Stand")book = Book.findByTitleLike("Harry Pot%")
book = Book.findByReleaseDateBetween( firstDate, secondDate )
book = Book.findByReleaseDateGreaterThan( someDate )
book = Book.findByTitleLikeOrReleaseDateLessThan( "%Something%", someDate )方法表达式
在GORM中一个方法表达式由前缀,比如 findBy
后面跟一个表达式组成,这个表达式由一个或多个属性组成。基本形式是:
Book.findBy([Property][Comparator][Boolean Operator])?[Property][Comparator]
def book = Book.findByTitle("The Stand")book = Book.findByTitleLike("Harry Pot%")Like
后缀, 它等价于SQL的 like 表达式.
可用的后缀包括:
InList - list中给定的值LessThan - 小于给定值LessThanEquals - 小于或等于给定值GreaterThan - 大于给定值GreaterThanEquals - 大于或等于给定值Like - 价于 SQL like 表达式Ilike - 类似于Like,但不是大小写敏感NotEqual - 不等于Between - 于两个值之间 (需要两个参数)IsNotNull - 不为null的值 (不需要参数)IsNull - 为null的值 (不需要参数)
你会发现最后三个方法标注了参数的个数,他们的示例如下:
def now = new Date()
def lastWeek = now - 7
def book = Book.findByReleaseDateBetween( lastWeek, now )books = Book.findAllByReleaseDateIsNull()
books = Book.findAllByReleaseDateIsNotNull()
布尔逻辑(AND/OR)
方法表达式也可以使用一个布尔操作符来组合两个criteria:
def books =
Book.findAllByTitleLikeAndReleaseDateGreaterThan("%Java%", new Date()-30)And 来确保两个条件都满足,
但是同样地你也可以使用 Or:
def books =
Book.findAllByTitleLikeOrReleaseDateGreaterThan("%Java%", new Date()-30)查询关联
关联也可以被用在查询中:
def author = Author.findByName("Stephen King")def books = author ? Book.findAllByAuthor(author) : []Author 实例不为null 我们在查询中用它取得给定
Author 的所有Book实例.
分页和排序
跟 list
方法上可用的分页和排序参数一样,他们同样可以被提供为一个map用于动态查询器的最后一个参数:
def books =
Book.findAllByTitleLike("Harry Pot%", [max:3,
offset:2,
sort:"title",
order:"desc"])def c = Account.createCriteria()
def results = c {
like("holderFirstName", "Fred%")
and {
between("balance", 500, 1000)
eq("branch", "London")
}
maxResults(10)
order("holderLastName", "desc")
}逻辑与(Conjunctions)和逻辑或(Disjunctions)
如前面例子所演示的,你可以用 and { }
块来分组criteria到一个逻辑AND:
and {
between("balance", 500, 1000)
eq("branch", "London")
}or {
between("balance", 500, 1000)
eq("branch", "London")
}not {
between("balance", 500, 1000)
eq("branch", "London")
}查询关联
关联可以通过使用一个跟关联属性同名的节点来查询. 比如我们说 Account
类有关联到多个 Transaction 对象:
class Account {
…
def hasMany = [transactions:Transaction]
Set transactions
…
}transaction
作为builder的一个节点来查询这个关联:
def c = Account.createCriteria()
def now = new Date()
def results = c.list {
transactions {
between('date',now-10, now)
}
}transactions 的
Account 实例. 你也可以在逻辑块中嵌套关联查询:
def c = Account.createCriteria()
def now = new Date()
def results = c.list {
or {
between('created',now-10,now)
transactions {
between('date',now-10, now)
}
}
}投影(Projections)查询
投影被用于定制查询结果. 要使用投影你需要在criteria
builder树里定义一个"projections"节点. projections节点内可用的方法等同于 Hibernate 的 Projections 类中的方法:
def c = Account.createCriteria()def numberOfBranches = c.get {
projections {
countDistinct('branch')
}
}使用可滚动的结果
Y你可以通过调用scroll方法来使用Hibernate的 ScrollableResults 特性:
def results = crit.scroll {
maxResults(10)
}
def f = results.first()
def l = results.last()
def n = results.next()
def p = results.previous()def future = results.scroll(10)
def accountNumber = results.getLong('number')结果集的迭代器(iterator)可以以任意步进的方式前后移动,而Query
/ ScrollableResults模式跟JDBC的PreparedStatement/
ResultSet也很像,其接口方法名的语意也跟ResultSet的类似.
不同于JDBC,结果列的编号是从0开始.
在Criteria实例中设置属性
如果在builder树内部的一个节点不匹配任何一项特定标准,它将尝试设置为Criteria对象自身的属性。因此允许完全访问这个类的所有属性。下面的例子是在Criteria
Criteria实例上调用 setMaxResults 和 setFirstResult:
import org.hibernate.FetchMode as FM
…
def results = c.list {
maxResults(10)
firstResult(50)
fetchMode("aRelationship", FM.EAGER)
}立即加载的方式查询
在 Eager
and Lazy Fetching立即加载和延迟加载
这节,我们讨论了如果指定特定的抓取方式来避免N+1查询的问题。这个criteria查询也可以做到:
def criteria = Task.createCriteria()
def tasks = criteria.list{
eq "assignee.id", task.assignee.id
join 'assignee'
join 'project'
order 'priority', 'asc'
}join 方法的用法. This method
indicates the criteria API that a JOIN query should be used
to obtain the results.
方法引用
如果你调用一个没有方法名的builder,比如:
默认的会列出所有结果,因此上面代码等价于:
| 方法 |
描述 |
|
| list |
这是默认的方法。它会返回所有匹配的行。 |
| get |
返回唯一的结果集,比如,就一行。criteria已经规定好了,仅仅查询一行。这个方法更方便,免得使用一个limit来只取第一行使人迷惑。 |
| scroll |
返回一个可滚动的结果集 |
| listDistinct |
如果子查询或者关联被使用,有一个可能就是在结果集中多次出现同一行,这个方法允许只列出不同的条目,它等价于 CriteriaSpecification 类的DISTINCT_ROOT_ENTITY |
GORM也支持Hibernate的查询语言HQL,在Hibernate文档中的
Chapter 14. HQL: The Hibernate Query Language
可以找到它非常完整的参考手册。
GORM提供了一些使用HQL的方法,包括 find,
findAll
和 executeQuery. 下面是一个查询的例子:
def results =
Book.findAll("from Book as b where b.title like 'Lord of the%'")位置和命名参数
上面的例子中传递给查询的值是硬编码的,但是,你可以同样地使用位置参数:
def results =
Book.findAll("from Book as b where b.title like ?", ["The Shi%"])def results =
Book.findAll("from Book as b where b.title like :search or b.author like :search", [search:"The Shi%"])多行查询
如果你需要将查询分割到多行你可以使用一个行连接符:
def results = Book.findAll("\
from Book as b, \
Author as a \
where b.author = a and a.surname = ?", ['Smith'])Groovy 的多行字符串对HQL查询无效
分页和排序
使用HQL查询的时候你也可以进行分页和排序。要做的只是简单指定分页和排序参数作为一个散列在方法的末尾调用:
def results =
Book.findAll("from Book as b where b.title like 'Lord of the%' order by b.title asc",
[max:10, offset:20])
beforeInsert - 对象持久到数据之前执行beforeUpdate - 对象被更新之前执行beforeDelete - 对象被删除之前执行afterInsert - 对象持久到数据库之后执行afterUpdate - 对象被更新之后执行afterDelete - 对象被删除之后执行onLoad - 对象从数据库中加载之后执行
为了添加一个事件需要在你的领域类中添加相关的闭包。
事件类型
beforeInsert事件
当一个对象保存到数据库之前触发
class Person {
Date dateCreated def beforeInsert = {
dateCreated = new Date()
}
}beforeUpdate事件
当一个对象被更新之前触发
class Person {
Date dateCreated
Date lastUpdated def beforeInsert = {
dateCreated = new Date()
}
def beforeUpdate = {
lastUpdated = new Date()
}
}beforeDelete事件
当一个对象被删除以后触发.
class Person {
String name
Date dateCreated
Date lastUpdated def beforeDelete = {
new ActivityTrace(eventName:"Person Deleted",data:name).save()
}
}onLoad事件
当一个对象被加载之后触发:
class Person {
String name
Date dateCreated
Date lastUpdated def onLoad = {
name = "I'm loaded"
}
}自动时间戳
上面的例子演示了使用事件来更新一个 lastUpdated 和 dateCreated
属性来跟踪对象的更新。事实上,这些设置不是必须的。通过简单的定义一个 lastUpdated 和 dateCreated
属性,GORM会自动的为你更新。
如果,这些行为不是你需要的,可以屏蔽这些功能。如下设置:
class Person {
Date dateCreated
Date lastUpdated
static mapping = {
autoTimestamp false
}
}这是必要的,如果你高兴地坚持以约定来定义GORM对应的表,列名等。你只需要这个功能,如果你需要定制GORM
映射到遗留模型或进行缓存
自定义映射是使用静态的mapping 块定义在你的域类中的:
class Person {
..
static mapping = { }
}表名
类映射到数据库的表名可以通过使用 table关键字来定制:
class Person {
..
static mapping = {
table 'people'
}
}people 表来代替默认的 person表.
列名
同样,也是可能的定制某个列到数据库。比如说,你想改变列名例子如下:
class Person {
String firstName
static mapping = {
table 'people'
firstName column:'First_Name'
}
}firstName). 接下来使用命名的 column, 来指定字段名称的映射.
列类型
GORM还可以通过DSL的type属性来支持Hibernate类型.
包括特定Hibernate的 org.hibernate.usertype.UserType 的子类, which allows
complete customization of how a type is persisted. 比如,有一个 PostCodeType
你可以象下面这样使用:
class Address {
String number
String postCode
static mapping = {
postCode type:PostCodeType
}
}class Address {
String number
String postCode
static mapping = {
postCode type:'text'
}
}postCode 映射到数据库的SQL
TEXT或者CLOB类型.
See the Hibernate documentation regarding Basic Types for further information.
一对一映射
在关联中,你也有机会改变外键映射联系,在一对一的关系中,对列的操作跟其他常规的列操作并无二异,例子如下:
class Person {
String firstName
Address address
static mapping = {
table 'people'
firstName column:'First_Name'
address column:'Person_Adress_Id'
}
}address 将映射到一个名称为 address_id
的外键. 但是使用上面的映射,我们改变外键列为 Person_Adress_Id.
一对多映射
在一个双向的一对多关系中,你可以象前节中的一对一关系中那样改变外键列,只需要在多的一端中改变列名即可。然而,在单向关联中,外键需要在关联自身中(即一的一端-译者注)指定。比如,给定一个单向一对多联系
Person 和 Address 下面的代码会改变 address
表中外键:
class Person {
String firstName
static hasMany = [addresses:Address]
static mapping = {
table 'people'
firstName column:'First_Name'
addresses column:'Person_Address_Id'
}
}address
表中有这个列,可以通过中间关联表来完成,只需要使用 joinTable 参数即可:
class Person {
String firstName
static hasMany = [addresses:Address]
static mapping = {
table 'people'
firstName column:'First_Name'
addresses joinTable:[name:'Person_Addresses', key:'Person_Id', column:'Address_Id']
}
}多对多映射
默认情况下, Grails中多对多的映射是通过中间表来完成的. 以下面的多对多关联为例:
class Group {
…
static hasMany = [people:Person]
}
class Person {
…
static belongsTo = Group
static hasMany = [groups:Group]
}group_person
表包含外键 person_id 和 group_id 对应 person
和 group 表. 假如你需要改变列名,你可以为每个类指定一个列映射.
class Group {
…
static mapping = {
people column:'Group_Person_Id'
}
}
class Person {
…
static mapping = {
groups column:'Group_Group_Id'
}
}class Group {
…
static mapping = {
people column:'Group_Person_Id',joinTable:'PERSON_GROUP_ASSOCIATIONS'
}
}
class Person {
…
static mapping = {
groups column:'Group_Group_Id',joinTable:'PERSON_GROUP_ASSOCIATIONS'
}
}设置缓存
Hibernate 本身提供了自定义二级缓存的特性. 这就需要在 grails-app/conf/DataSource.groovy
文件中配置:
hibernate {
cache.use_second_level_cache=true
cache.use_query_cache=true
cache.provider_class='org.hibernate.cache.EhCacheProvider'
}想了解更多Hibernate的二级缓存,参考 Hibernate documentation 相关文档.
缓存实例
假如要在映射代码块中启用缺省的缓存,可以通过调用 cache
方法实现:
class Person {
..
static mapping = {
table 'people'
cache true
}
}class Person {
..
static mapping = {
table 'people'
cache usage:'read-only', include:'non-lazy'
}
}缓存关联对象
就像使用Hibernate的二级缓存来缓存实例一样,你也可以来缓存集合(关联),比如:
class Person {
String firstName
static hasMany = [addresses:Address]
static mapping = {
table 'people'
version false
addresses column:'Address', cache:true
}
}
class Address {
String number
String postCode
}cache:'read-write' // or 'read-only' or 'transactional'
Caching Queries
You can cache queries such as dynamic finders
and criteria. To do so using a dynamic finder you can pass the cache
argument:
def person = Person.findByFirstName("Fred", cache:true)Note that in order for the results
of the query to be cached, you still need to enable caching in your
mapping as discussed in the previous section.
You can also cache criteria queries:
def people = Person.withCriteria {
like('firstName', 'Fr%')
cache true
}缓存用法
下面是不同缓存设置和他们的使用方法:
read-only - 假如你的应用程序需要读但是从不需要更改持久化实例,只读缓存或许适用.read-write - 假如你的应用程序需要更新数据,读-写缓存或许是合适的.nonstrict-read-write -
假如你的应用程序仅偶尔需要更新数据(也就是说,如果这是极不可能两笔交易,将尝试更新同一项目同时)并且时进行) ,并严格交易隔离,是不是需要一个nonstrict-read-write可能是适宜的.transactional - transactional
缓存策略提供支持对全事务缓存提供比如JBoss的TreeCache. 这个缓存或许仅仅使用在一个JTA环境,同时你必须在 grails-app/conf/DataSource.groovy
文件中的 hibernate 配置中 hibernate.transaction.manager_lookup_class.
默认情况下GORM 类使用
table-per-hierarchy
来映射继承的. 这就有一个缺点就是在数据库层面,列不能有
NOT-NULL
的约束。如果你更喜欢
table-per-subclass
你可以使用下面方法:
class Payment {
Long id
Long version
Integer amount static mapping = {
tablePerHierarchy false
}
}
class CreditCardPayment extends Payment {
String cardNumber
}Payment 类的映射设置中,指定了在所有的子类中,不使用
table-per-hierarchy 映射.
你可以通过DSL来定制GORM生成数据库标识,缺省情况下GORM将根据原生数据库机制来生成ids,这是迄今为止最好的方法,但是仍存在许多模式,不同的方法来生成标识。
为此,Hibernate特地定义了id生成器的概念,你可以自定义它要映射的id生成器和列,如下:
class Person {
..
static mapping = {
table 'people'
version false
id generator:'hilo', params:[table:'hi_value',column:'next_value',max_lo:100]
}
}想了解更多不同的Hibernate生成器请参考 Hibernate文档
注意,如果你仅仅想定制列id,你可以这样:
class Person {
..
static mapping = {
table 'people'
version false
id column:'person_id'
}
}class Person {
String firstName
String lastName static mapping = {
id composite:['firstName', 'lastName']
}
}firstName 和 lastName
属性来创建一个复合id。当你后面需要通过id取一个实例时,你必须用这个对象的原型:
def p = Person.get(new Person(firstName:"Fred", lastName:"Flintstone"))
println p.firstName
class Person {
String firstName
String address
static mapping = {
table 'people'
version false
id column:'person_id'
firstName column:'First_Name', index:'Name_Idx'
address column:'Address', index:'Name_Idx, Address_Index'
}
}version
属性,此属性将映射数据库中的一个
version
列.
如果你映射的是一个遗留数据库(已经存在的数据库--译者注),
这将是一个问题,因此可以通过如下方法来关闭这个功能:
class Person {
..
static mapping = {
table 'people'
version false
}
}如果你关闭了乐观锁 你将自己负责并发更新并且存在用户丢失数据的风险
(due to data overriding) 除非你使用 悲观锁
延迟加载集合
就像在 立即加载和延迟加载,
部分讨论的,默认情况下,GORM 集合使用延迟加载的并且可以通过 fetchMode 来配置,
但如果你更喜欢把你所有的映射都集中在 mappings 代码块中,你也可以使用ORM的DSL来配置获取模式:
class Person {
String firstName
static hasMany = [addresses:Address]
static mapping = {
addresses lazy:false
}
}
class Address {
String street
String postCode
}延迟加载单向关联
在GORM中,one-to-one和many-to-one关联缺省是非延迟加载的.这在有很多实体(数据库记录-译者注)的时候,会产生性能问题,尤其是关联查询是以新的SELECT语句执行的时候.
此时你应该将one-to-one和many-to-one关联的延迟加载象集合那样进行设置:
class Person {
String firstName
static belongsTo = [address:Address]
static mapping = {
address lazy:true // lazily fetch the address
}
}
class Address {
String street
String postCode
}Person 的 address属性为延迟加载.
正如
级联更新
这节描述的,控制更新和删除的主要机制是从关联一端到
belongsTo
静态属性的一端。
然而,通过cascade属性,ORM
DSL可以让你访问Hibernate的 transitive persistence 能力。
有效级联属性的设置包括:
- create - 创建从关联端到另一端的级联
- merge - 合并 detached 联合
- save-update - 只级联保存和更新
- delete - 只级联删除
- lock - 关联的悲观锁是否被级联
- refresh - 级联refreshes
- evict - cascades evictions (equivalent to discard() in GORM)
to associations if set
- all - 级联所有操作
- delete-orphan - Applies only to one-to-many associations and
indicates that when a child is removed from an association then it
should be automatically deleted
获得级联样式更好的理解和用法的介绍,请阅读Hibernate文档的transitive persistence章节
使用上述的值定义一个或多个级联属性(逗号分隔):
class Person {
String firstName
static hasMany = [addresses:Address]
static mapping = {
addresses cascade:"all,delete-orphan"
}
}
class Address {
String street
String postCode
}embedded
属性) 把一个表分成多个对象。 你也可以通过Hibernate的自定义用户类型实现相同的效果。这不是领域类本身,而是java或者groovy类。
所有这些类型都有一个继承自org.hibernate.usertype.UserType
org.hibernate.usertype.UserType
的"meta-type"类。
Hibernate参考手册
有一些自定义类型资料,在这里我们将重点放在如何在Grails中映射。让我们看一个使用老式的(Java 1.5以前)枚举类型安全的领域类:
class Book {
String title
String author
Rating rating static mapping = {
rating type: RatingUserType
}
}rating 的枚举类型和在自定义映射UserType中设置属性的类型。这是你想使用自定义类型所必须做的。你也可以使用其他列的设置,比如使用"column"来改变列名和使用"index"把它添加到index。
自定义类型不局限于只是一个列,他们可以映射到多列。在这种情况下,你必须在映射中明确地定义那列使用,
因为Hibernate只能为一列使用属性名。 幸运的是,Grails可以为属性映射多列:
class Book {
String title
Name author
Rating rating static mapping = {
name type: NameUserType, {
column name: "first_name"
column name: "last_name"
}
rating type: RatingUserType
}
}author属性创建"first_name"和"last_name"列。You'll
be pleased to know that you can also use some of the normal
column/property mapping attributes in the column definitions. For
example:
column name: "first_name", index: "my_idx", unique: true
type, cascade,
lazy, cache, and joinTable.
One thing to bear in mind with custom types is
that they define the SQL types for the
corresponding database columns. That helps take the burden of
configuring them yourself, but what happens if you have a legacy
database that uses a different SQL type for one of the columns? In that
case, you need to override column's SQL type using the sqlType
attribute:
class Book {
String title
Name author
Rating rating static mapping = {
name type: NameUserType, {
column name: "first_name", sqlType: "text"
column name: "last_name", sqlType: "text"
}
rating type: RatingUserType, sqlType: "text"
}
}def airports = Airport.list(sort:'name')
class Airport {
…
static mapping = {
sort "name"
}
}class Airport {
…
static mapping = {
sort name:"desc"
}
}class Airport {
…
static hasMany = [flights:Flight]
static mapping = {
flights sort:'number'
}
}def transferFunds = {
Account.withTransaction { status ->
def source = Account.get(params.from)
def dest = Account.get(params.to) def amount = params.amount.toInteger()
if(source.active) {
source.balance -= amount
if(dest.active) {
dest.amount += amount
}
else {
status.setRollbackOnly()
}
}
}
}String name
String description
column name | data type
description | varchar(255)
column name | data type
description | TEXT
static constraints = {
description(maxSize:1000)
}影响字符串类型属性的约束
如果 maxSize 或者 size
约束被定义, Grails将根据约束的值设置列的最大长度.
通常, 不建议在同一个的领域类中组合使用这些约束. 但是, 如果你非要同时定义 maxSize
和 size 约束的话, Grails将设置列的长度为 maxSize
约束和size上限约束的最少值. (Grails使用两者的最少值,因此任何超过最少值的长度将导致验证错误.)
如果定义了inList约束 (maxSize 和 size
未定义), 字段最大长度将取决于列表(list)中最长字符串的的长度. 以"Java"、"Groovy"和"C++"为例,
Grails将设置字段的长度为6("Groovy"的最长含有6个字符).
影响数值类型属性的约束
如果定义了 max、min 或者range约束,
Grails将基于约束的值尝试着设置列的精度. (设置的结果很大程度上依赖于Hibernate跟底层数据库系统的交互程度.)
通常来说,
不建议在同一领域类的属性上组合成双的min/max和range约束,但是如果这些约束同时被定义了,那么Grails将使用约束值中的最少精度值.
(Grails取两者的最少值,是因为任意超过最少精度的长度将会导致一个验证错误.)
如果定义了scale约束, 那么Grails会试图使用基于约束的值来设置列的 标度(scale) . 此规则仅仅应用于浮点数值
(比如,java.lang.Float,java.Lang.Double, java.lang.BigDecimal及其相关的子类).
(设置的结果同样也是很大程度上依赖于Hibernate跟底层数据库系统的交互程度.)
约束定义着数值的最小/最大值, Grails使用数字的最大值来设置其精度.
切记仅仅指定min/max约束中的一个,是不会影响到数据库的生成的 (因为可能会是很大的负值,比如当max是100),
,除非指定的约束值要比Hibernate默认的精度(当前是19)更高.比如...
someFloatValue(max:1000000, scale:3)
someFloatValue DECIMAL(19, 3) // precision is default
someFloatValue(max:12345678901234567890, scale:5)
someFloatValue DECIMAL(25, 5) // precision = digits in max + scale
someFloatValue(max:100, min:-100000)
someFloatValue DECIMAL(8, 2) // precision = digits in min + default scale